
SOFAStack Scalable Open Financial Architecture Stack 是蚂蚁金服自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,是在金融场景里锤炼出来的最佳实践。

本文为《剖析 | SOFAJRaft 实现原理》第二篇,本篇作者米麒麟,来自陆金所。《剖析 | SOFAJRaft 实现原理》系列由 SOFA 团队和源码爱好者们出品,项目代号:SOFA:JRaftLab/,目前领取已经完成,感谢大家的参与。
SOFAJRaft 是一个基于 Raft 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。
SOFAJRaft :
前言
SOFAJRaft-RheaKV 是基于 SOFAJRaft 和 RocksDB 实现的嵌入式、分布式、高可用、强一致的 KV 存储类库,SOFAJRaft 是基于 Raft 一致性算法的生产级高性能 Java 实现,支持 Multi-Raft-Group。SOFAJRaft-RheaKV 集群主要包括三个核心组件:PD,Store 和 Region。本文将围绕 SOFAJRaft-RheaKV 架构设计,存储概览,核心模块,使用场景以及基于 Raft 实现等方面剖析 SOFAJRaft-RheaKV 基于 SOFAJRaft 实现原理,阐述如何使用 Raft 协议支持 KV 存储类库功能特性:
- SOFAJRaft-RheaKV 基础架构如何设计?核心组件负责哪些功能?模块内部处理流程是怎样?
- 基于 SOFAJRaft 如何使用 Raft 实现 SOFAJRaft-RheaKV 强一致性和自驱动等特性?
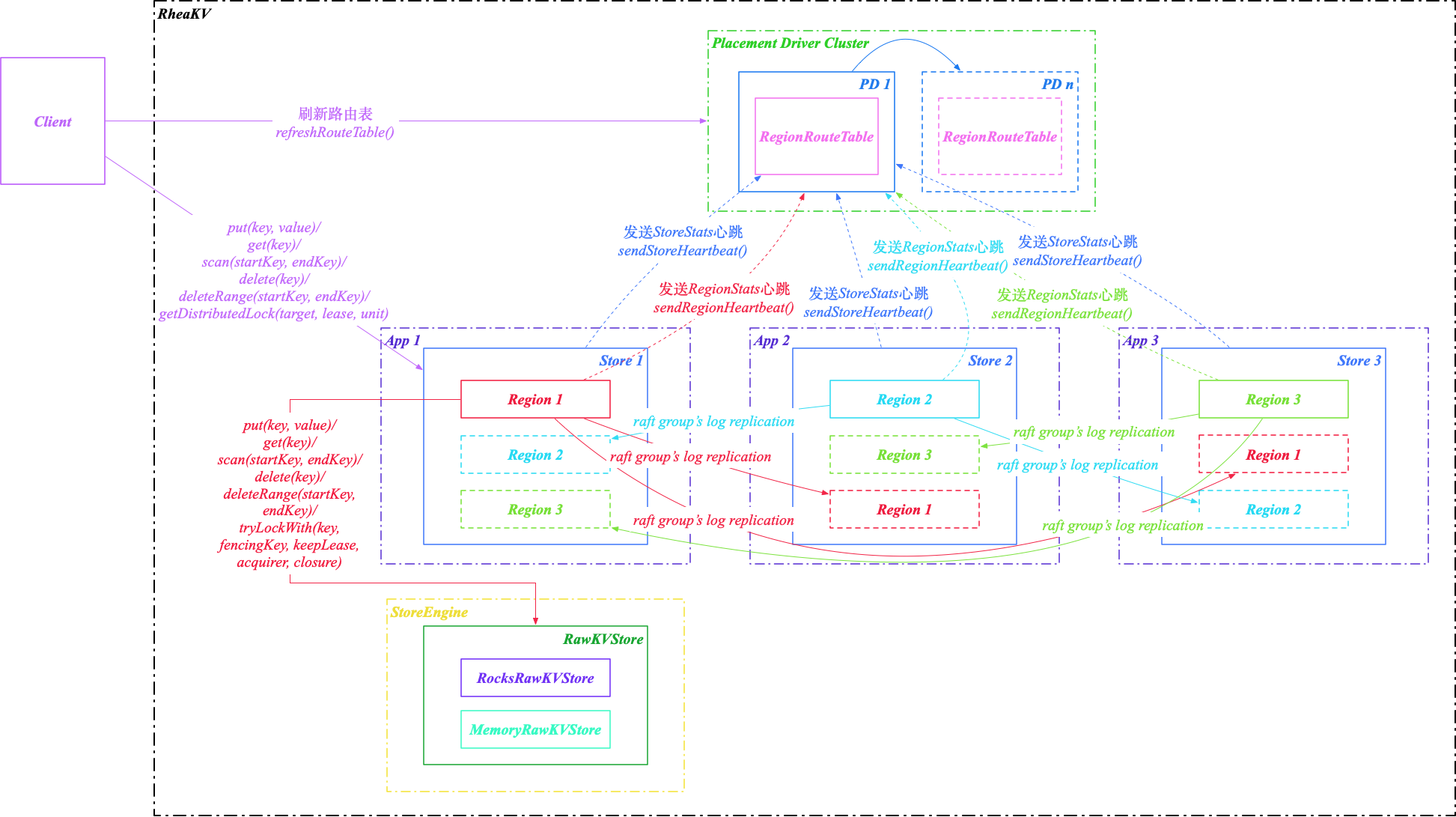
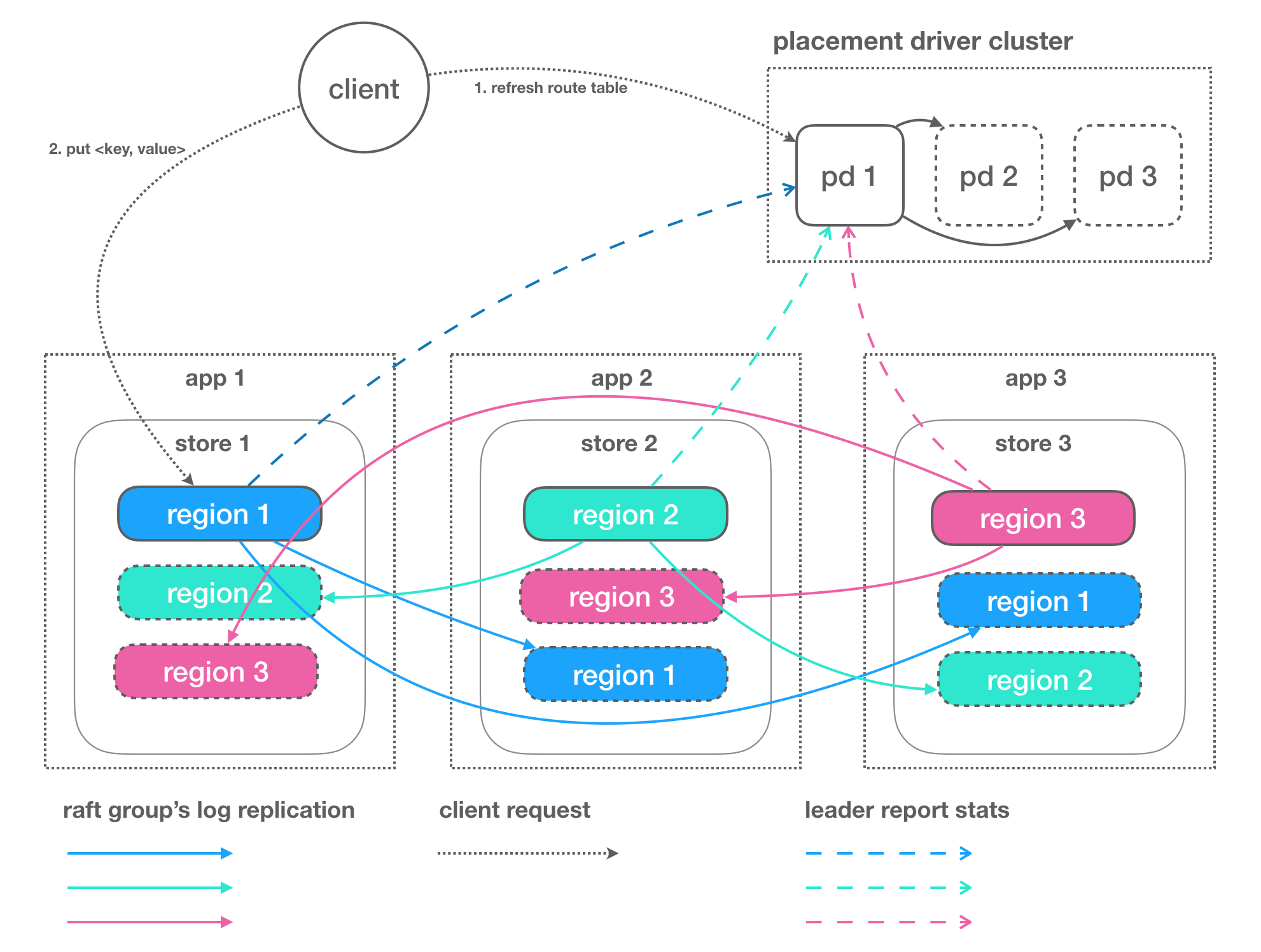
SOFAJRaft-RheaKV 概览
SOFAJRaft-RheaKV 是一个轻量级的分布式的嵌入式的 KV 存储 Library, RheaKV 包含在 SOFAJRaft 项目里,是 SOFAJRaft 的子模块。SOFAJRaft-RheaKV 定位是嵌入式 jar 包方式嵌入到应用中,涵盖以下功能特性:
- 强一致性,基于 Multi-Raft 分布式一致性协议保证数据可靠性和一致性;
- 自驱动,自诊断,自优化,自决策,自恢复;
- 可监控基于节点自动上报到 PD 的元信息和状态信息;
- 基本 API get/put/delete 和跨分区 scan/batch put,distributed lock 等。
架构设计
SOFAJRaft-RheaKV 存储类库主要包括 PD,Store 和 Region 三个核心组件,支持轻量级的状态/元信息存储以及集群同步,分布式锁服务使用场景:
- PD 是全局的中心总控节点,负责整个集群的调度管理,维护 RegionRouteTable 路由表。一个 PDServer 管理多个集群,集群之间基于 clusterId 隔离;PD Server 需要单独部署,很多场景其实并不需要自管理,RheaKV 也支持不启用 PD,不需要自管理的集群可不启用 PD,设置 PlacementDriverOptions 的 fake选项为 true 即可。
- Store 是集群中的一个物理存储节点,一个 Store 包含一个或多个 Region。
- Region 是最小的 KV 数据单元,可理解为一个数据分区或者分片,每个 Region 都有一个左闭右开的区间 [startKey, endKey),能够根据请求流量/负载/数据量大小等指标自动分裂以及自动副本搬迁。Region 有多个副本 Replication 构建 Raft Groups 存储在不同的 Store 节点,通过 Raft 协议日志复制功能数据同步到同 Group 的全部节点。
存储设计
SOFAJRaft-RheaKV 存储层为可插拔设计,实现 RawKVStore 存储接口,目前 StoreEngine 存储引擎支持 MemoryDB 和 RocksDB 两种实现:
- MemoryRawKVStore:MemoryDB 基于 ConcurrentSkipListMap 实现,有更好的性能,但是单机存储容量受内存限制;
- RocksRawKVStore:RocksDB 在存储容量上只受磁盘限制,适合更大数据量的场景。
SOFAJRaft-RheaKV 存储引擎基于 MemoryDB 和 RocksDB 实现 KV 存储入口:
com.alipay.sofa.jraft.rhea.storage.RawKVStorecom.alipay.sofa.jraft.rhea.storage.MemoryRawKVStorecom.alipay.sofa.jraft.rhea.storage.RocksRawKVStore
SOFAJRaft-RheaKV 数据强一致性依靠 SOFAJRaft 同步数据到其他副本 Replication, 每个数据变更都会落地为一条 Raft 日志, 通过 Raft 协议日志复制功能将数据安全可靠地同步到同 Raft Group 的全部节点里。
核心设计
SOFAJRaft-RheaKV 核心模块包括 KV 模块[RheaKVStore 基于 RegionRouteTable 路由表使用 RaftRawKVStore 存储 KeyValue],PD 模块[PlacementDriverServer 基于 StoreHeartbeat/RegionHeartbeat 心跳平衡节点分区 Leader 以及分裂]。
KV 模块内部处理
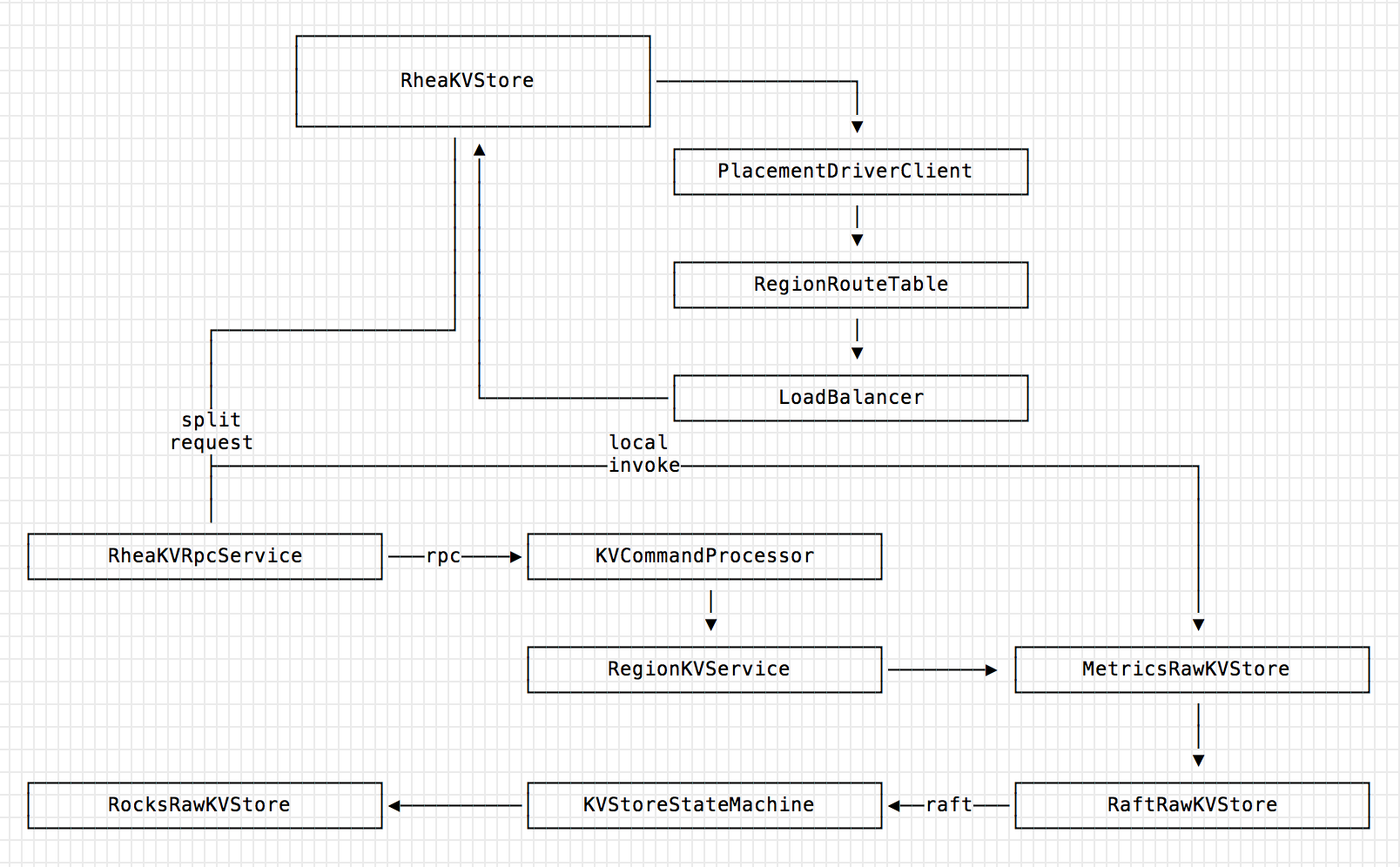
- RheaKVStore:最上层 User API,默认实现为 DefaultRheaKVStore, RheaKVStore 为纯异步实现,所以通常阻塞调用导致的客户端出现瓶颈,理论上不会在 RheaKV 上遭遇,DefaultRheaKVStore 实现包括请求路由、Request 分裂、Response 聚合以及失败重试等功能。
- PlacementDriverClient:非必须,作为与 PlacementDriver Server 集群沟通的客户端,通过它获取集群完整信息包括但不仅限于"请求路由表",对于无 PD 场景, RheaKV 提供 Fake PD Client。
- RegionRouteTable:分片逻辑基于 RegionRouteTable 路由表结构,最适合的数据结构便是跳表或者二叉树(最接近匹配项查询)。作为本地路由表缓存组件,RegionRouteTable 根据 KV 请求的具体失败原因来决策是否从 PD Server 集群刷新数据,并且提供对单个 Key、多个 Key 列表以及 Key Range 进行计算返回对应的分区 ID。选择 Region 的 StartKey 作为 RegionRouteTable 的 Key ,主要取决于 Region Split 的方式,父 Region 分裂成两个子 Region 导致其中一个子 Region 的 StartKey 为 SplitKey。
- LoadBalancer:在提供 Follower 线性一致读的配置下有效,目前仅支持 RR 策略。
- RheaKVRpcService:针对 KV 存储服务的 RPC Client 客户端封装,实现 Failover 逻辑。
- RegionKVService:KV Server 服务端的请求处理服务,一个 StoreEngine 中包含很多 RegionKVService, 每个 RegionKVService 对应一个 Region,只处理本身 Region 范畴内的请求。
- MetricsRawKVStore:拦截请求做指标度量。
- RaftRawKVStore:RheaKV 的 Raft 入口,从这里开始 Raft 流程。
- KVStoreStateMachine:实现 Raft 状态机。
- RocksRawKVStore:原始的 RocksDB API 封装, 目前 RheaKV 也支持可插拔的 MemoryDB 存储实现。
PD 模块内部处理
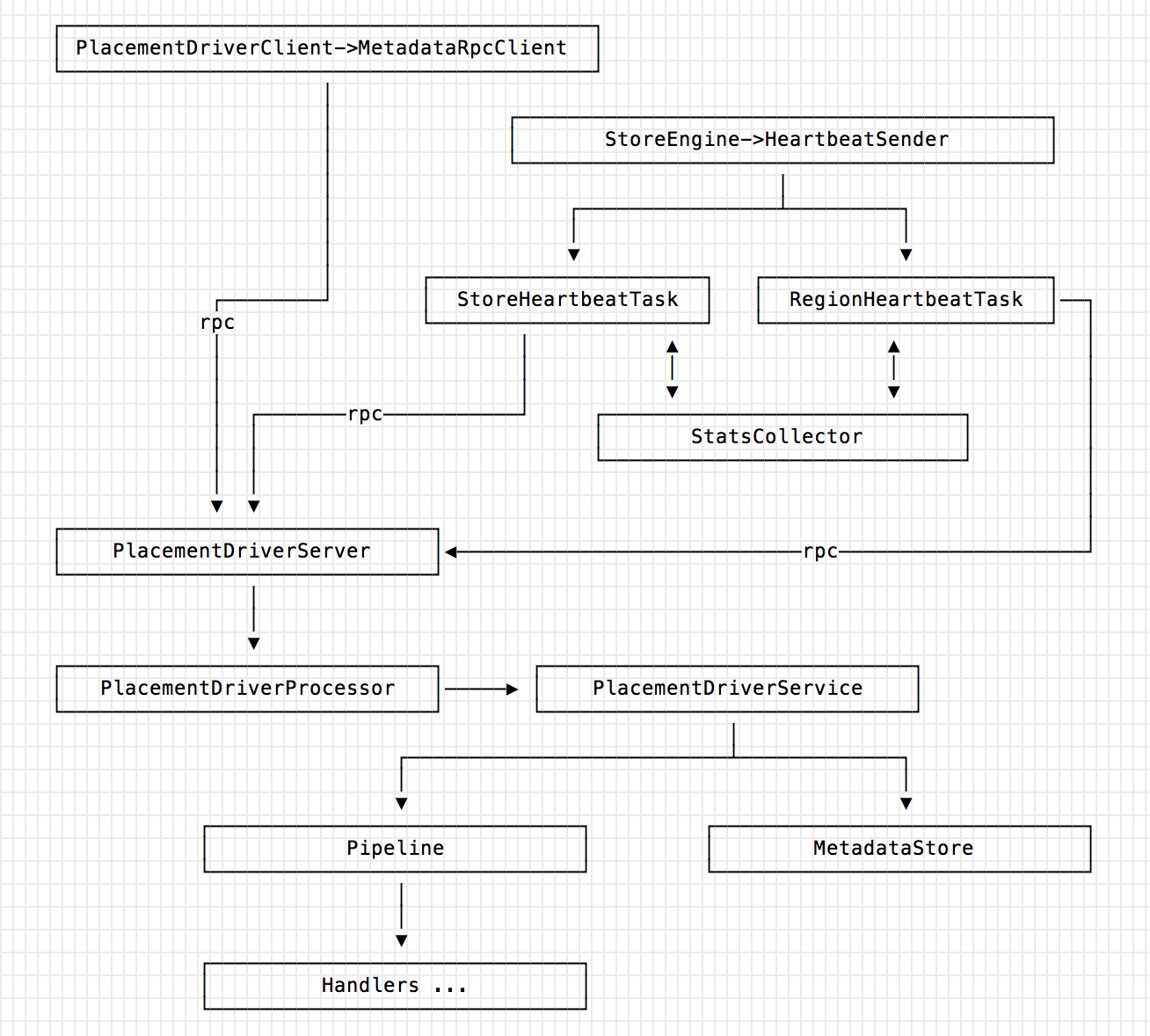
PD 模块主要参考 TIKV 的设计理念,目前只实现自动平衡所有节点的分区 Leader 以及自动分裂。
- PlacementDriverClient -> MetadataClient:MetadataClient 负责从 PD 获取集群元信息以及注册元信息。
- StoreEngine -> HeartbeatSender:
- HeartbeatSender 负责发送当前存储节点的心跳,心跳中包含一些状态信息,心跳一共分为两类:StoreHeartbeat 和 RegionHeartbeat;
- PD 不断接受 RheaKV 集群这两类心跳消息,PD 在对 Region Leader 的心跳回复里面包含具体调度指令,再以这些信息作为决策依据。除此之外,PD 还应该可以通过管理接口接收额外的运维指令,用来人为执行更准确的决策。
- 两类心跳包含的状态信息详细内容如下:
- StoreHeartbeat 包括存储节点 Store 容量,Region 数量,Snapshot 数量以及写入/读取数据量等 StoreStats 统计明细;
- RegionHeartbeat 包括 Region 的 Leader 位置,掉线 Peer 列表,暂时不 Work 的 Follower 以及写入/读取数据量/Key 的个数等 RegionStats 统计明细。
- Pipeline:是针对心跳上报 Stats 的计算以及存储处理流水线,处理单元 Handler 可插拔非常方便扩展。
- MetadataStore:负责集群元信息存储以及查询,存储方面基于内嵌的 RheaKV。
SOFAJRaft-RheaKV 剖析
RheaKV 是基于 SOFAJRaft 实现的嵌入式、分布式、高可用、强一致的 KV 存储类库,TiKV 是一个分布式的 KV 系统,采用 Raft 协议保证数据的强一致性,同时使用 MVCC + 2PC 方式实现分布式事务的支持,两者如何基于 Raft协议实现 KV 存储?
RheaKV 基于 JRaft 实现
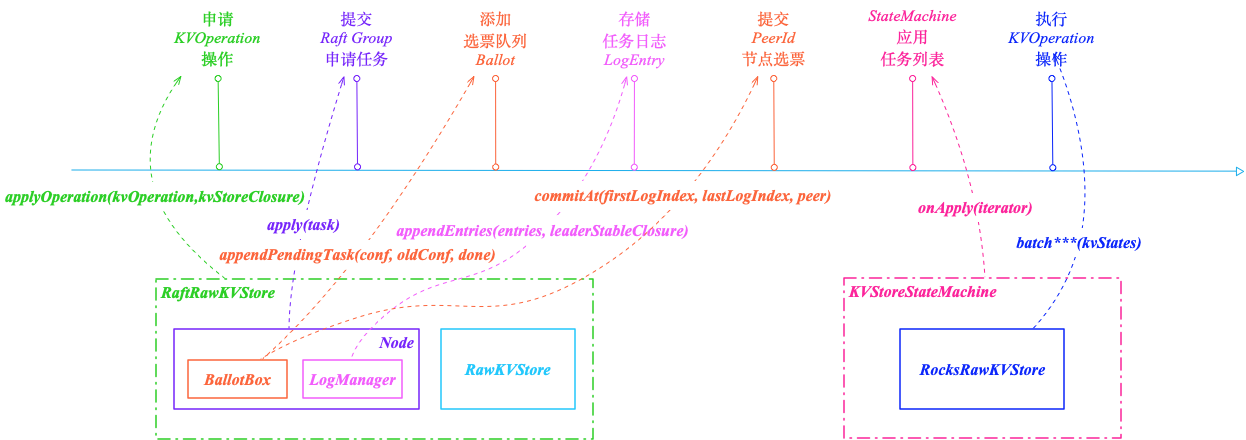
RaftRawKVStore 是 RheaKV 基于 Raft 复制状态机 KVStoreStateMachine 的 RawKVStore 接口 KV 存储实现,调用 applyOperation(kvOperation,kvStoreClosure) 方法根据读写请求申请指定 KVOperation 操作,申请键值操作处理逻辑:
- 检查当前节点的状态是否为 STATE_LEADER,如果当前节点不是 Leader 直接失败通知 Done Closure,通知失败(NOT_LEADER)后客户端刷新 Leader 地址并且重试。Raft 分组 Leader 节点调用 Node#apply(task) 提交申请基于键值操作的任务到相应 Raft Group,向 Raft Group 组成的复制状态机集群提交新任务应用到业务状态机,Raft Log 形成 Majority 后 StateMachine#onApply(iterator) 接口应用到状态机的时候会被获取调用。Node 节点构建申请任务日志封装成事件发布回调,发布节点服务事件到队列 applyQueue,依靠 Disruptor 的 MPSC 模型批量消费,对整体吞吐性能有着极大的提升。日志服务事件处理器以单线程 Batch 攒批的消费方式批量运行键值存储申请任务;
- Raft 副本节点 Node 执行申请任务检查当前状态是否为 STATE_LEADER,必须保证 Leader 节点操作申请任务。循环遍历节点服务事件判断任务的预估任期是否等于当前节点任期,Leader 没有发生变更的阶段内提交的日志拥有相同的 Term 编号,节点 Node 任期满足预期则 Raft 协议投票箱 BallotBox 调用 appendPendingTask(conf, oldConf, done) 日志复制之前保存应用上下文,即基于当前节点配置以及原始配置创建选票 Ballot 添加到选票双向队列 pendingMetaQueue;
- 日志管理器 LogManager 调用底层日志存储 LogStorage#appendEntries(entries) 批量提交申请任务日志写入 RocksDB,用于 Leader 向 Follower 复制日志包括心跳存活检查等。日志管理器发布 Leader 稳定状态回调 LeaderStableClosure 事件到队列 diskQueue 即 Disruptor 的 Ring Buffer,稳定状态回调事件处理器通过MPSC Queue 模型攒批消费触发提交节点选票;
- 投票箱 BallotBox 调用 commitAt(firstLogIndex, lastLogIndex, peerId) 方法提交当前 PeerId 节点选票到 Raft Group,更新日志索引在[first_log_index, last_log_index]范畴。通过 Node#apply(task) 提交的申请任务最终将会复制应用到所有 Raft 节点上的状态机,RheaKV 状态机通过继承 StateMachineAdapter 状态机适配器的 KVStoreStateMachine 表示;
- Raft 状态机 KVStoreStateMachine 调用 onApply(iterator) 方法按照提交顺序应用任务列表到状态机。当 onApply(iterator) 方法返回时认为此批申请任务都已经成功应用到状态机上,假如没有完全应用(比如错误、异常)将被当做 Critical 级别错误报告给状态机的 onError(raftException) 方法,错误类型为 ERROR_TYPE_STATE_MACHINE。Critical 错误导致终止状态机,为什么这里需要终止状态机,非业务逻辑异常的话(比如磁盘满了等 IO 异常),代表可能某个节点成功应用到状态机,但是当前节点却应用状态机失败,是不是代表出现不一致的错误? 解决办法只能终止状态机,需要手工介入重启,重启后依靠 Snapshot + Raft log 恢复状态机保证状态机数据的正确性。提交的任务在 SOFAJRaft 内部用来累积批量提交,应用到状态机的是 Task迭代器,通过 com.alipay.sofa.jraft.Iterator 接口表示;
- KVStoreStateMachine 状态机迭代状态输出列表积攒键值状态列表批量申请 RocksRawKVStore 调用 batch***(kvStates) 方法运行相应键值操作存储到 RocksDB,为啥 Batch 批量存储呢? 刷盘常用伎俩,攒批刷盘优于多次刷盘。通过 RecycleUtil 回收器工具回收状态输出列表,其中KVStateOutputList 是 Pooled ArrayList 实现,RecycleUtil 用于释放列表对象池化复用避免每次创建 List。
RheaKV 基于状态机 KVStoreStateMachine 的 RaftRawKVStore 存储 Raft 实现入口:
com.alipay.sofa.jraft.rhea.storage.RaftRawKVStore
RheaKV 运行在每个 Raft 节点上面的状态机 KVStoreStateMachine 实现入口:
com.alipay.sofa.jraft.rhea.storage.KVStoreStateMachine
RheaKV 是一个要保证线性一致性的分布式 KV 存储引擎,所谓线性一致性,一个简单的例子是在 T1 的时间写入一个值,那么在 T1 之后读一定能读到这个值,不可能读到 T1 之前的值。因为 Raft 协议是为了实现分布式环境下面线性一致性的算法,所以通过 Raft 非常方便的实现线性 Read,即将任何的读请求走一次 Raft Log,等 Log 日志提交之后在 apply 的时候从状态机里面读取值,一定能够保证此读取到的值是满足线性要求的。因为每次 Read 都需要走 Raft 流程,所以性能是非常的低效的,SOFAJRaft 实现 Raft 论文提到 ReadIndex 和 Lease Read 优化,提供基于 Raft 协议的 ReadIndex 算法的更高效率的线性一致读实现,ReadIndex 省去磁盘的开销,结合 SOFAJRaft 的 Batch + Pipeline Ack + 全异步机制大幅度提升吞吐。RaftRawKVStore 接收 get/multiGet/scan/getSequence 读请求都使用 Node``#``readIndex``(``requestContext``, ``readIndexClosure``) 发起一次线性一致读请求,当能够安全读取的时候传入的 ReadIndexClosure 将被调用,正常情况从状态机中读取数据返回给客户端,readIndex 读取失败尝试应用键值读操作申请任务于 Leader 节点的状态机 KVStoreStateMachine,SOFAJRaft 保证读取的线性一致性。线性一致读在任何集群内的节点发起,并不需要强制要求放到 Leader 节点上面,将请求散列到集群内的所有节点上,降低 Leader 节点的读取压力。RaftRawKVStore 的 get 读操作发起一次线性一致读请求的调用:
// KV 存储实现线性一致读public void get(final byte[] key, final boolean readOnlySafe, final KVStoreClosure closure) { if (!readOnlySafe) { this.kvStore.get(key, false, closure); return; } // 调用 readIndex 方法,等待回调执行 this.node.readIndex(BytesUtil.EMPTY_BYTES, new ReadIndexClosure() { @Override public void run(final Status status, final long index, final byte[] reqCtx) { if (status.isOk()) { // ReadIndexClosure 回调成功,从 RawKVStore 调用 get 方法读取最新数据返回 RaftRawKVStore.this.kvStore.get(key, true, closure); return; } // 特殊情况譬如发生选举读请求失败,尝试申请 Leader 节点的状态机 RaftRawKVStore.this.readIndexExecutor.execute(() -> { if (isLeader()) { LOG.warn("Fail to [get] with 'ReadIndex': {}, try to applying to the state machine.", status); // If 'read index' read fails, try to applying to the state machine at the leader node applyOperation(KVOperation.createGet(key), closure); } else { LOG.warn("Fail to [get] with 'ReadIndex': {}.", status); // Client will retry to leader node new KVClosureAdapter(closure, null).run(status); } }); } });} TiKV 基于 Raft 实现
TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到 Group 的多数节点。TiKV 整体架构包括 Placement Driver,Node,Store 以及 Region 组件:
- Placement Driver : Placement Driver (PD) 负责整个集群的管理调度。
- Node : Node 可以认为是一个实际的物理机器,每个 Node 负责一个或者多个 Store。
- Store : Store 使用 RocksDB 进行实际的数据存储,通常一个 Store 对应一块硬盘。
- Region : Region 是数据移动的最小单元,对应的是 Store 里面一块实际的数据区间。每个 Region 有多个副本(Replica),每个副本位于不同的 Store ,而这些副本组成了一个 Raft group。
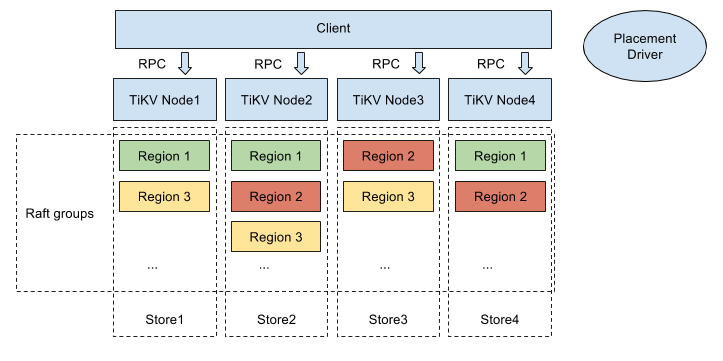
TiKV 使用 Raft 一致性算法来保证数据的安全,默认提供的是三个副本支持,这三个副本形成了一个 Raft Group。当 Client 需要写入 TiKV 数据的时候,Client 将操作发送给 Raft Leader,在 TiKV 里面称做 Propose,Leader 将操作编码成一个 Entry,写入到自己的 Raft Log 里面,称做 Append。Leader 也会通过 Raft 算法将 Entry 复制到其他的 Follower 上面,叫做 Replicate。Follower 收到这个 Entry 之后也会同样进行 Append 操作,顺带告诉 Leader Append 成功。当 Leader 发现此 Entry 已经被大多数节点 Append,认为此 Entry 已经是 Committed 的,然后将 Entry 里面的操作解码出来,执行并且应用到状态机里面,叫做 Apply。TiKV 提供 Lease Read,对于 Read 请求直接发给 Leader,如果 Leader 确定自身的 Lease 没有过期,那么直接提供 Read 服务不用执行一次 Raft 流程。如果 Leader 发现 Lease 已经过期,就会强制执行一次 Raft 流程进行续租然后再提供 Read 服务。TiKV 是以 Region 为单位做数据的复制,也就是一个 Region 的数据保存多个副本,将每一个副本叫做一个 Replica。Replica 之间是通过 Raft 来保持数据的一致,一个 Region 的多个 Replica 保存在不同的节点上构成一个 Raft Group,其中一个 Replica 作为此 Group 的 Leader,其他的 Replica 作为 Follower。所有的读和写都是通过 Leader 进行,再由 Leader 复制给 Follower。
总结
本文围绕 SOFAJRaft-RheaKV 架构存储,模块流程以及基于 Raft 实现细节方面阐述 SOFAJRaft-RheaKV 基本原理,剖析 SOFAJRaft-RheaKV 如何使用 JRaft 一致性协议日志复制功能保证数据的安全和容灾,参考 TiKV 基于 Raft 算法实现了分布式环境数据的强一致性。
系列阅读
欢迎参加 SOFAMeetup#2 上海站

SOFA Meetup #2 上海站《使用 SOFAStack 快速构建微服务》期待你的参与❤~
5 月 26 日,本周日,SOFAStack 开源核心成员集体出动。本期我们将侧重于各个落地的实际场景进行架构解析。
分布式事务 Seata 详解、与 Spring Cloud 生态的融合案例、使用 SOFAStack 快速构建微服务 Demo 实操、更有最新开源的《让 AI 像 SQL 一样简单 — SQLFlow Demo 》首秀,周日不见不散~
戳链接即可报名: